论文笔记(一)
Deep Learning for Sentiment Analysis: A Survey
定义
语义分析和意见挖掘是研究人们对待实体(entities)的 意见(opinions), 情感(sentiments), 情绪(emotions), 评价(appraisals)和 态度(attitudes)
传统方法
| 有监督 | 无监督 |
|---|---|
| SVM、Maximum Entropy、NB | sentiment lexicons、grammatical analysis、syntactic patterns |
Word Embedding
| methods | note |
|---|---|
| Word2Vec | Continuous Bag-of-Words model (CBOW), Skip-Gram model (SG) |
| Global Vector (GloVe) | trained on the nonzero entries of a global word-word co-occurrence matrix |
| BERT | SOTA |
深度学习方法
RNN/CNN/LSTM/Attention/Memory Network/RecNN
Sentiment Analysis Tasks
由简到繁(对象的粒度)
| 层次 | note |
|---|---|
| document level | 一整个文档对某个实体的意见评估:pos/neg |
| sentence level | subjectivity classification: 判断一句话是主观还是客观,若为主观,再判断pos/neg/neu |
| aspect level | 判断一句话有几个层次(实体),对它们的情感aspect extraction, entity extraction, and aspect sentiment classification |
除此之外,情感分析还做emotion analysis, sarcasm detection, multilingual sentiment analysis这些方向。
Document Level
Sentiment classification at the document level is to assign an overall sentiment orientation/polarity to an opinion document, i.e., To determine whether the document (e.g., a full online review) conveys an overall positive or negative opinion.
document表示:BoW模型(忽略词序、语法、句法)→n-gram→dense vector,BERT?
网络模型:DNN、CNN、RNN、LSTM、Hierarchical Attention Network
推荐阅读:HAN for Document Classification
Sentence Level
Sentence level sentiment classification is to determine the sentiment expressed in a single given sentence.
语法语义分析、解析树
Aspect Level
Aspect level sentiment classification considers both the sentiment and the target information. A target is usually an entity or an entity aspect. For simplicity, both entity and aspect are usually just called aspect.
For example, in the sentence “the screen is very clear but the battery life is too short.” the sentiment is positive if the target aspect is “screen” but negative if the target aspect is “battery life”.
三个重点:
- represent the context of a target. 生成目标对象上下文的表示:可以使用之前提到的文本表示方法
- generate a target representation. 生成目标对象的表示:可以类似词嵌入,学习一个文本嵌入(target embedding)
- identify the important sentiment context (words) for the specified target. 识别对于特定目标对象的重要情感上下文:目前常用注意力机制处理,但是还没有统治性的方法出现。
Aspect extraction & categorization
自动aspect(实体)抽取
可以建模为一个序列标注问题
Opinion expression extraction
意见表达提取,旨在识别句子或文档中的情感表达
identify the expressions of sentiment in a sentence or a document.
Sentiment composition
Sentiment composition claims that the sentiment orientation of an opinion expression is determined by the meaning of its constituents as well as the grammatical structure.
Opinion holder extraction
意见发表者提取
Temporal opnion mining
时态意见挖掘,预测未来观点。随着时间推移,观点会发生改变。
Sentiment analysis with word embedding
词嵌入的情感分析。词嵌入在情感分析模型中起着重要作用。
Sarcasm analysis
讽刺分析
Sarcasm Detection: A Comparative Study
Emotion analysis
情绪分析。主要的情绪包括爱、喜悦、惊讶、愤怒、悲伤和恐惧。情绪的概念与情感密切相关。
Multimodal data for sentiment analysis
多模态数据的情感分析。如承载文本、视觉和听觉信息的数据,已经被用来帮助情感分析,提供额外的情感信号。
multimodal sentiment analysis Benchmarks
Resource-poor languages and multilingual sentiment analysis
资源贫乏语言与多语言情感分析
参考
RoBERTa
从模型上来说,RoBERTa基本没有什么太大创新,主要是在BERT基础上做了几点调整:
训练时间更长,batch size更大,训练数据更多;
移除了next predict loss;
训练序列更长;
动态调整Masking机制。
Byte level BPE RoBERTa is trained with dynamic masking (Section 4.1),
FULL - SENTENCES without NSP loss (Section 4.2),
large mini-batches (Section 4.3) and a larger byte-level BPE (Section 4.4).
ELECTRA
创新
- 提出了新的模型预训练的框架,采用generator和discriminator的结合方式,但又不同于GAN
- 将Masked Language Model的方式改为了replaced token detection
- 因为masked language model 能有效地学习到context的信息,所以能很好地学习embedding,所以使用了weight sharing的方式将generator的embedding的信息共享给discriminator
- dicriminator 预测了generator输出的每个token是不是original的,从而高效地更新transformer的各个参数,使得模型的熟练速度加快
- 该模型采用了小的generator以及discriminator的方式共同训练,并且采用了两者loss相加,使得discriminator的学习难度逐渐地提升,学习到更难的token(plausible tokens)
- 模型在fine-tuning 的时候,丢弃generator,只使用discriminator
参考:
XLNet
BERT方法的预训练和微调过程的差异性:预训练时输入的部分词被mask,而微调时并不存在mask词。XLNet优点:
- 通过最大化因式分解顺序的所有排列的预期可能性来学习双向语境
- 自回归,使得输入可以不限长度
- 融合Transformer-XL思路
AR or AE ?
AR(Auto-regressive)
- 前一个词的输出作为预测这个词的输入
- 无法获得双向语境信息
- ELMo(双向的AR)、GPT
- 给定文本序列$\bold{x}=[x_1, …x_T]$,目标是调整参数使得训练数据上的似然函数最大:

AE(Auto-encoding)
- 即:mask方法,可使用双向的信息
- [mask] 信息没有被使用
- Fine-tuning阶段看不到这种被强行加入的 [mask] 标记,两个阶段存在使用模式不一致的情形,可能带来一定的性能损失
- BERT 通过将序列 $\bold{x}$ 中随机挑选 15% 的 Token 变成 [MASK] 得到带噪声版本的 $\hat{\bold{x}}$。假设被 Mask 的原始值为$\bar{\bold{x}}$,那么 BERT 希望尽量根据上下文恢复(猜测)出原始值,也就是
 表示$t$位置是一个[mask],即只需要求 [mask] 掉位置的概率,$x'$ 代表除 $x$ 外的序列中所有词。
表示$t$位置是一个[mask],即只需要求 [mask] 掉位置的概率,$x'$ 代表除 $x$ 外的序列中所有词。
XLNet出发点:融合两者的优点,具体来说,站在AR的角度,引入和双向语言模型等价的效果。使得模型看上去仍然是从左向右的输入和预测模式,但是其实内部已经引入了当前单词的下文信息
Permutation language model
具体实现方式:通过随机取一句话的随机排列的一种,然后将末尾一定量的词给 “遮掩”(和 BERT 里的直接替换 “[MASK]” 有些不同)掉,最后用 AR 的方式来按照这种排列方式依此预测被 “遮掩” 掉的词。目标不是具体要预测哪个词,而是谁在最后,就预测谁。

挑选最后的几个做mask呢?设置超参数K,K等于总长度除以需要预测的个数,如:K=7/2,论文中给出实验最佳K值介于6和7之间,取倒数:$(\frac{1}{7}, \frac{1}{6})$,而BERT中的15%恰好处于之间。
对于一个长度为T的句子,为节省计算量,只随机采样 $T!$ 里的部分排列,$Z_T$ 表示长度为 T 的序列的所有排列的集合,$z\in Z_T$ 是其中一种排列,$z_t$ 表示排列的第 $t$ 个元素,而 $z_{<t}$ 表示 $z$ 的第 1 到 t-1 个元素
Permutation LM的目标使似然概率最大(从所有的排列中采样一种,然后根据这个排列来分解联合概率成条件概率的乘积,然后加起来)

如何Permute?
Permutation 具体的实现方式不是打乱输入句子的顺序(在fine-tuning阶段也不可能实现),而是通过对 Transformer 的 Attention Mask 进行操作

比如序号为1234的句子,随机取一种排列3241,Attention mask如上图,第 $e_{ij}$ 为红色代表打乱后的排序下第 $i$ 个元素能知道第 $j$ 个元素的信息,白色为不知道。
具体的,在 Transformer 内部,通过 Attention 掩码,从 $\bold{x}$ 的输入单词里面,也就是 $x_i$ 的上文和下文单词中,随机选择 $i-1$ 个,放到 $x_i$ 的上文位置中,把其它单词的输入通过 Attention 掩码隐藏掉,于是就能够达成我们期望的目标(当然这个所谓放到 $x_i$ 的上文位置,只是一种形象的说法,其实在内部,就是通过 Attention Mask ,把其它没有被选到的单词 Mask 掉,不让它们在预测单词 $x_i$ 的时候发生作用而已。看着就类似于把这些被选中的单词放到了上文 Context_before 的位置了)。
位置信息?
直接使用这个方法会产生问题:
假设输入的句子是”I like New York”,并且一种排列为 z=[1, 3, 4, 2],假设我们需要预测的是 $z_3=4$ 根据公式:
$p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_4=x|x_1x_3)=\dfrac{\mathrm{exp}(e(x)^Th_\theta (x_1x_3))}{\sum_{x’}\mathrm{exp}(e(x’)^Th_\theta(x_1x_3))}$
式中 $x$ = York,$z_i$ 代表打乱排列后的第 i 个词,$x_i$ 代表原本序列中的第 i 个词。另外我们再假设一种排列为 z’=[1,3,2,4],我们需要预测 $z_3=2$ 根据公式:
$p_\theta(X_{z_3}=x|x_{z_1z_2})=p_\theta(X_2=x|x_1x_3)=\dfrac{\mathrm{exp}(e(x)^Th_\theta (x_1x_3))}{\sum_{x’}\mathrm{exp}(e(x’)^Th_\theta(x_1x_3))}$
可以看出,二者的结果是一样的,即问题出在模型并不知道要预测的那个词在原始序列中的位置。(注意 Transformer 输入了位置编码,但位置编码是和输入的 Embedding 加到一起作为输入的,即 $x_1, x_3$ 带有正确的位置信息,但对于需要预测的 $z_3$ ,模型是不知道位置信息的)所以需要“显式”地告诉模型需要预测的原始位置信息。
$p_\theta(X_{z_t}=x|\bold{x}{z<t})=\dfrac{\mathrm{exp}(e(x)^T g_\theta (\bold{x}{z_{<t}},z_t))}{\sum_{x’}\mathrm{exp}(e(x’)^T g_\theta (\bold{x}{z{<t}},z_t))}$
上式中的 $g_\theta (\bold{x}{z{<t}},z_t)$ 表示一个包含词 $\bold{x}{z{<t}}$ 和位置信息 $z_t$ 的新模型。
Two-Stream Self-Attention
如何表示 $g_\theta$ ,需要满足两点要求:
- 预测 $\bold{x}{z_t}$,$g_\theta$ 只能使用位置信息 $z_t$ 而不能直接使用 $\bold{x}{z_t}$
- 为了预测 $z_t$ 之后的词,$g_\theta$ 必须编码 $\bold{x}_{z_t}$ 的信息
解决方法:使用包含两个隐状态的模型
- 内容隐状态 content stream: $h_\theta(\bold{x}{z{\leq t}})$ ,和标准的Transformer一样,既编码上下文,也编码 $x_{z_t}$ 本身。
- 查询隐状态 query stream: $g_\theta(\bold{x}{z{<t}},z_t)$,只编码上下文和要预测的位置 $z_t$,但是不包括 $x_{z_t}$ 本身。用于代替Bert中的 [mask] 标记。
计算过程,从 $m=1$ 到第 $M$ 层逐层计算:

梯度更新和标准的Self-Attention一样,在fine-tune的时候可以丢掉query流只使用content流。(二者权重共享?)
模型的大致结构:

假设排列为3-2-4-1,并且现在预测第 1 个位置(原排列的位置1,重组排列后的位置4)的词的概率。
图a中是Content流的计算,可以参考所有4个词的Content,因此$K&V=[h_1^{(0)},h_2^{(0)},h_3^{(0)},h_4^{(0)}]$,$Q=h_1^{(0)}$,其实就是标准的Transformer的计算过程
图b中是Query流的计算,不能参考自己的内容,因此$K&V=[h_1^{(0)},h_2^{(0)},h_3^{(0)}]$,$Q=g_1^{(0)}$
图c中是完整计算过程,首先 $h$ 和 $g$ 分别被初始化为 $e(x_i)$ 和 $W$,然后分别计算得到第一层的输出,注意右边的 attention mask 区别
for content stream:

for query stream:

Transformer-XL
Segment Recurrence Mechanism 段循环机制
简单介绍一下:解决了Transformer不能一次性输入太长文本的问题。可以理解为Transformer+RNN

对长序列进行分段,在前一段计算完后,将它计算出的隐状态都保存下来,存到一个 Memeory 中,之后在计算当前段的时候,将之前存下来的隐状态和当前段的隐状态拼起来,作为 Attention 机制的 K 和 V,从而获得更长的上下文信息
Relative Position Encoding 相对位置编码
- Transformer中考虑了序列的位置信息,在分段的情况下,如果仅仅对于每个段仍直接使用 Transformer 中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。比如,第 i−2 段和第 i−1 段的第一个位置将具有相同的位置编码,但它们对于第 i 段重要性显然并不相同
- 相对位置编码,不再关心句中词的绝对位置信息,而是相对的,比如说两个词之间隔了多少个词这样的相对信息
Relative Segment Encoding 相对段编码?
- 改进 Bert 中的 NSP 任务
- 和 BERT 一样,选择两个句子,它们有 50% 的概率是连续的句子(前后语义相关),有 50% 的概率是不连续(无关) 的句子。把这两个句子拼接后当成一个句子来学习 Permutation LM。输入和 BERT 是类似的:[A, SEP, B, SEP, CLS]。
- BERT 使用的是绝对的 Segment 编码,也就是第一个句子对于的 Segment id 是 0,而第二个句子是 1。这样如果把两个句子换一下顺序,那么输出是不一样的。XLNet 使用的是相对的 Segment 编码,它是在计算 Attention 的时候判断两个词是否属于同一个 Segment,如果位置 i 和 j 的词属于同一个 segment,那么使用一个可以学习的 Embedding $s_{ij}=s+$,否则 $s_{ij}=s−$,也就是说,我们只关心它们是属于同一个 segment 还是属于不同的 segment。
- 计算 attention 时:$a_{ij}=(q_i+b)^T s_{ij}$,其中 $q_i$ 是第 $i$ 个位置的 query 向量。
- 最后我们会把这个 attention score 加到原来计算的 attention weight 里,这样它就能学到当 i 和 j 都属于某个 segment 的特征,以及 i 和 j 属于不同 segment 的特征
XLNet 与 Bert 对比
假设输入是 [New, York, is, a, city] ,并且假设恰巧XLNet和BERT都选择使用 [is, a, city] 来预测 ‘New’ 和 ‘York’。同时我们假设XLNet的排列顺序为 [is, a, city, New, York] 。那么它们优化的目标函数分别为:
$\jmath_{\mathrm{BERT}} = \mathrm{log} p(\mathrm{New}|\mathrm{is\ a\ city}) + \mathrm{log} p(\mathrm{York}|\mathrm{is\ a\ city})$
$\jmath_{\mathrm{XLNet}} = \mathrm{log} p(\mathrm{New}|\mathrm{is\ a\ city}) + \mathrm{log} p(\mathrm{York}|\mathrm{is\ a\ city\ New})$
可以发现,XLNet可以在预测York的使用利用New的信息,因此它能学到”New York”经常出现在一起而且它们出现在一起的语义和单独出现是完全不同的。
代码部分
data_utils.py
Sentence piece 模型
读取每一个文件的每一行,然后使用sp切分成WordPiece,然后变成id,放到数组input_data里。另外还有一个sent_ids,用来表示句子。对于每一个文件(我们这里只有一个),最终是为了得到”input_data, sent_ids = [], []”两个list。
1 | input_data=[19 5372 19317 6014 111 17634 2611 19 1084 111 420 152 25 6096 26 8888] |
第一个句子是”我的空调漏水怎么办”,使用sp切分后变成”[‘▁’, ‘我的’, ‘空调’, ‘漏’, ‘水’, ‘怎么’, ‘办’]”,最后变成ID得到[19, 5372, 19317, 6014, 111, 17634, 2611]。而sent_ids是[ True True True True True True True]。
sent_ids可以判断哪些ID是属于一个句子的,也就是sent_ids通过交替的True和False来告诉我们句子的边界
拼接句子需要保证反转句子的最后一个 sent_id 与下一句第一个不同。
生成 Pretrain 数据:{ 64(reuse_len) A [sep] B [sep] [CLS] } 共128。
固定64个作为cache。然后从i+reuse_len位置开始不断寻找句子,直到这些句子的Token数大于61(128-64-3)。
参考
论文解读:
https://wmathor.com/index.php/archives/1475/
https://zhuanlan.zhihu.com/p/110204573
https://zhuanlan.zhihu.com/p/70257427
代码解读:
https://blog.csdn.net/weixin_37947156/article/details/100315836
BERT-CHN-WWM
wwm(whole word masking) or N-gram mask?

- wwm: 虽然 token 是最小的单位,但在 [MASK] 的时候是基于分词的
- N-gram Masking: 是对连续n个词进行 [MASK],如图中把“语 言 模 型”都 [MASK 了,就是一个 2-gram Masking。虽然[MASK]是对分词后的结果进行,但在输入的时候还是单个的token。
- MacBERT: 采用基于分词的 n-gram masking,1-gram~4-gram Masking的概率分别是40%、30%、20%、10%。
预训练任务
Mac(MLM as correction)
- 使用全词掩码和N-gram掩码
- 取消 [mask] token,而使用随机近义词替换,如果没有近义词,使用随机替换
- 15% input,80% 替换为近义词,10% 随机替换,10% 不替换
SOP(sentence order prediction)
结构和NSP一样,两个句子是连续的为正例,负例为交换原文两句子顺序
ERNIE-THU
与K-BERT的不同是,ERNIE的token和entity用的两套注意力机制参数,然后合并时再用一套参数,而K-BERT是直接把知识插入到原来的句子里,只使用一套注意力机制的参数。



Detail
T-Encoder单独使用了token-input,和BERT一样: ${\boldsymbol{w_1,…,w_n}}=\mathrm{T-Encoder}({w_1,…,w_n})$ 。
K-Encoder使用了T-encoder处理后的token-input和TransE处理后的entity embedding: ${\boldsymbol{w^o_1,…,w^o_n}},{\boldsymbol{e^o_1,…,e^o_m}}=\mathrm{K-Encoder}({\boldsymbol{w_1,…,w_n}},{\boldsymbol{e_1,…,e_m}})$
在K-Enocder中,token-input和entity-input使用的是两套不同参数的mh-att:
${\boldsymbol{\tilde{w_j}^{(i)}}}=\mathrm{MH-ATT}_1({\boldsymbol{w_j^{(i-1)}}}),$
${\boldsymbol{\tilde{e_k}^{(i)}}}=\mathrm{MH-ATT}_2({\boldsymbol{e_k^{(i-1)}}})$
size: $N = 6, M = 6, H_w = 768,H_e = 100,A_w = 12,A_e = 4$
参数量:114M (BERT-base: 12-layer, 768-hidden, 12-heads, 110M)
knowledgeable module of ERNIE is much smaller than the language module and has little impact on the run-time performance.
information fusion
对于一个有对应实体的token:

对于没有对应实体的token:

作为下一个K-encoder的输入
Size of $h_j$: intermediate_size=3072
TransE
Instead of directly using the graph-based facts in KGs, we encode the graph structure of KGs with knowledge embedding algorithms like TransE (Bordes et al., 2013), and then take the informative entity embeddings as input for ERNIE.
entity使用TransE的嵌入表示然后再输入到K-Encoder
ERNIE中的entity注入方式是通过注入entity的embedding(嵌入)来隐含所有关于entity的信息
预训练方式 dEA
denoising entity auto-encoder (dEA)
随机mask一些 token-entity alignments(词-实体的组合),模型根据 aligned tokens $w_i$ 去预测entities $e_k$。

- 5% 对于一个token-entity alignment,随机替换entity,让模型预测正确的entity
- 15% 随机mask掉 token-entity alignments,让模型正确预测token-entity alignment
- 剩下的时间不改变
cross-entropy loss function
MLM和NSP任务同时进行,总损失是dEA, MLM, NSP的损失之和
Fine-tuning for specific tasks

对于普通的分类任务,采用的仍然是[CLS]作为输出,对一些knowledge driven的任务,比如:
- relation classificaiton 增加 [ENT] token
- entity typing 增加 [HD] [TL] token
GLUE Result

Ablation study
On FewRel (%)

参考
论文 https://arxiv.org/abs/1905.07129
代码 https://github.com/thunlp/ERNIE
https://www.jiqizhixin.com/articles/2019-05-26-4
https://zhuanlan.zhihu.com/p/103208601
百度/清华 ERNIE https://blog.csdn.net/LoseInVain/article/details/113859683
ERNIE-Baidu 1.0
ERNIE Github: https://github.com/PaddlePaddle/ERNIE
Knowledge Masking
模型在预测未知词的时候,没有考虑到外部知识。但是如果我们在mask的时候,加入了外部的知识,模型可以获得更可靠的语言表示。
例如: 哈利波特是J.K.罗琳写的小说。 单独预测
哈[MASK]波特或者J.K.[MASK]琳对于模型都很简单,但是模型不能学到哈利波特和J.K. 罗琳的关系。如果把哈利波特直接MASK掉的话,那模型可以根据作者,就预测到小说这个实体,实现了知识的学习。
需要注意的是这些知识的学习是在训练中隐性地学习,而不是直接将外部知识的embedding加入到模型结构中(ERNIE-TsingHua的做法),模型在训练中学习到了更长的语义联系,例如说实体类别,实体关系等,这些都使得模型可以学习到更好的语言表达。
ERNIE的mask的策略是通过三个阶段学习的,在第一个阶段,采用的是BERT的模式basic-level masking,然后在加入词组的mask(phrase-level masking),通过一些语义分割工具判断短语和实体;然后在加入实体级别entity-level的mask。

更多的语料信息
包括一些对话的数据
ERNIE-Baidu 2.0
Continual Pre-training
- 初始化 optimized initialization 每次有新任务过来,持续学习的框架使用的之前学习到的模型参数作为初始化,然后将新的任务和旧的任务一起训练。
- 训练任务安排 task allocating 对于多个任务,框架将自动的为每个任务在模型训练的不同阶段安排N个训练轮次,这样保证了有效率地学习到多任务。如何高效的训练,每个task 都分配有N个训练iteration。 One left problem is how to make it trained more efficiently. We solve this problem by allocating each task N training iterations. Our framework needs to automatically assign these N iterations for each task to different stages of training. In this way, we can guarantee the efficiency of our method without forgetting the previously trained knowledge
- 部分任务的语义信息建模适合递进式
- 比如ernie1.0 突破完形填空
- ernie2.0 突破选择题,句子排序题等
- 不断递进更新,就好像是前面的任务都是打基础,有点boosting的意味
- 顺序学习容易导致遗忘模式(这个可以复习一下李宏毅的视频),所以只适合学习任务之间比较紧密的任务,就好像你今天学了JAVA,明天学了Spring框架,但是如果后天让你学习有机化学,就前后不能够联系起来,之前的知识就忘得快
- 适合递进式的语音建模任务: MLM word -> whole word -> name entity
Pre-training tasks
ERNIE模型堆叠了大量的预训练目标。
词法层级的任务(word-aware pretraining task):获取词法知识。
knowledge masking(1.0) ERNIE1.0的任务
大小写预测(Capitalization Prediction Task) 模型预测一个字不是不是大小写,这个对特定的任务例如NER比较有用。(但是对于中文的话,这个任务比较没有用处,可能可以改为预测某个词是不是缩写)
词频关系(Token-Document Relation Prediction Task) 预测一个词是不是会多次出现在文章中,或者说这个词是不是关键词。
语法层级的任务(structure-aware pretraining task) :获取句法的知识
句子排序(Sentence Reordering Task) 把一篇文章随机分为i = 1到m份,对于每种分法都有 i! 种组合,所以总共有$\sum_{i=i}^m i!$种组合,让模型去预测这篇文章是第几种,就是一个多分类的问题。这个问题就能够让模型学到句子之间的顺序关系。就有点类似于Albert的SOP任务的升级版。
句子距离预测(Sentence Distance Task) 一个三分类的问题:
- 0: 代表两个句子相邻
- 1: 代表两个句子在同个文章但不相邻
- 2: 代表两个句子在不同的文章中
语义层级的任务(semantic-aware pretraining task) :获取语义关系的知识
篇章句间关系任务(Discourse Relation Task) 判断句子的语义关系例如logical relationship( is a, has a, contract etc.)
信息检索关系任务(IR Relevance Task) 一个三分类的问题,预测query和网页标题的关系
- 0: 代表了提问和标题强相关(出现在搜索的界面且用户点击了)
- 1: 代表了提问和标题弱相关(出现在搜索的界面但用户没点击)
- 2: 代表了提问和标题不相关(未出现在搜索的界面)
Continual Fine-tuning
参考:https://zhuanlan.zhihu.com/p/103190005
Trans家族模型
TransE
希望学出一个简单的模型,将实体和实体之间的关系表示成向量。
TransE,通过将关系表示为在embedding空间中的平移来建模。也就是把头实体和尾实体都表示成向量,然后用“头实体+关系=尾实体”去优化损失。
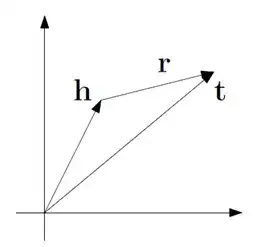
对于一个三元组 (h,l,t),其中h是头实体,t是尾实体,l是它们的关系,TransE希望它们的嵌入表示 (h,l,t)有如下关系: t≈h+l,也就是说t要和h+l尽可能接近。反之,如果这三者不构成三元组,则要尽可能远离。
损失函数
Hinge loss:

S为正例三元组,S’为负例,S‘的构建是随机替换正例三元组中的h或者t得到。d是l1或l2距离。
梯度(以L2-norm,对h求导为例):

若为L1-norm,梯度为[1,-1,-1,…]的形式。
训练过程

- 随机初始化实体e和关系l的表示向量,正则化关系l;
- 每一轮训练都重新将实体e正则化(batch norm);
- 随机采样出一批正例,对每一条正例采样一些负例;
- 用hinge loss更新embedding参数。
Loss更新的参数,是所有entities和relations的Embedding数据,每一次SGD更新的参数就是一个Batch中所有embedding的值
训练数据集:FB15K,WN18
代码:https://github.com/zqhead/TransE
更多
知识图谱嵌入的Translate模型汇总(TransE,TransH,TransR,TransD)https://zhuanlan.zhihu.com/p/147542008
知识图谱相关论文
19/20年相关论文
商汤/阿里企业的论文
PELT
pluggable entity lookup table
为了得到domain-specific的预训练模型,一般需要再训练或者引入外部知识图谱,这里为了不用再训练(耗时耗力),不用引入外部知识图谱,
直接在已有经典预训练模型比如bert/roberta上面做些操作(就是直接把所有entity mention对应的output embedding加起来,相对比较简单的一个操作),得到实体嵌入,将传统的词嵌入和现在的实体嵌入一起放进去做表征。
Knowledge Graph Embedding by Adaptive Limit Scoring Loss Using Dynamic Weighting Strategy
Knowledge graph embedding aims to represent entities and relations as low-dimensional vectors, which is an effective way for predicting missing links in knowledge graphs. Designing a strong and effective loss framework is essential for knowledge graph embedding models to distinguish between correct and incorrect triplets. The classic margin-based ranking loss limits the scores of positive and negative triplets to have a suitable margin. The recently proposed Limit-based Scoring Loss independently limits the range of positive and negative triplet scores. However, these loss frameworks use equal or fixed penalty terms to reduce the scores of positive and negative sample pairs, which is inflexible in optimization. Our intuition is that if a triplet score deviates far from the optimum, it should be emphasized. To this end, we propose Adaptive Limit Scoring Loss, which simply re-weights each triplet to highlight the less-optimized triplet scores. We apply this loss framework to several knowledge graph embedding models such as TransE, TransH and ComplEx. The experimental results on link prediction and triplet classification show that our proposed method has achieved performance on par with the state of the art.
Do Pre-trained Models Benefit Knowledge Graph Completion? A Reliable Evaluation and a Reasonable Approach 预训练模型是否有利于KGC?
补充:KGC任务
KGC任务旨在补全知识图中缺失的三元组 (h, r, t)。
有两种主要的方法来完成这个任务,即链接预测和三元组分类
- 前者主要预测三重查询(h,r,?), (h,r,?)或(?,r,t), (?,r,t)
- 后者的目的是确定给定的三元(h,r,t), (h,r,t)是否正确。
补充:KG-BERT (2019)
通过语言模型来判断知识图谱三元组是否合理,方法是直接将{h, r, t}拼接为一个句子输入,通过Bert模型来判断合理性

或者输入{h, t}判断关系r类型

性能不佳的两个原因
不准确的评估设置
大多数现有的KGC模型都是在封闭世界假设(Closed-world Assumption, CWA)下进行评估的:在给定的KGs中未知的任何知识(没有出现的三元组)都是不正确的。这样的设置有利于自动构建数据集,而无需手动注释。然而,PLMs的引入带来的很多未知的外部知识,都是在CWA下被认为是不正确的,这错误地降低了模型的性能。
开放世界假设 (Open-world assumption, OWA)认为知识图谱中包含的三元组是不完备的。因此,开放世界假设下的评估更准确、更接近真实场景,但需要额外的人工标注,仔细验证知识图谱中不存在的完整三元组是否正确。

没有正确利用语言模型
直接拼接{h, r, t}作为语言模型输入会导致句子不连贯问题
PKGC模型
一种新的基于PLM的KGC模型,基本思想是将每个三元组转换成自然的提示句,而不是简单地拼接它们的标签。具体来说,为每个关系类型手动定义提示模板,并进一步引入软提示,以更好地表达三元组的语义。此外,得益于提示的调整,PKGC可以灵活地考虑三元组的上下文,例如定义和属性,将它们作为支持提示插入三元组提示的末尾。

Soft prompts: ?文章中没有详细说
训练任务
链接预测和三元组分类,前者主要为三元查询(h, r, ?)或(?, r, t),后者旨在判断给定的三元组(h, r, t)是否正确。
在三元组分类任务中,需要人工帮助判断负类的三元组(一小部分)是否真的是错误的(CWA假设)
Analysis
//
Relational World Knowledge Representation in Contextual Language Models: A Review 知识图谱综述
https://arxiv.org/abs/2104.05837
论文详解:https://zhuanlan.zhihu.com/p/419803461
基于知识图谱的知识推理
Prompt learning
Prompt learning 相关文章 https://github.com/thunlp/PromptPapers
open-source prompt-learning toolkit https://github.com/thunlp/OpenPrompt
Prompt learning入门 https://zhuanlan.zhihu.com/p/442486331
Basic
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
Prompt 是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的文本的技术。
对于输入的文本x,使用函数$f$,将x转化为prompt形式x’
该函数通常进行两步操作:
- 使用一个模板,模板通常为一段自然语言,并且包含有两个空位置:用于填输入x的位置[X]和用于生成答案文本z的位置[Z].
- 把输入x填到[X]的位置。
例如:
x = “ I love this movie.”
模版:[X] Overall, it was a [Z] movie.
x’ = I love this movie. Overall it was a [Z] movie.
接着进行答案搜索,LM寻找填在[Z]处可以使得分数最高的文本 z 。
最后是答案映射。
Prompt设计
Prompt形状
Prompt的形状主要指的是[X]和[Z]的位置和数量。上文提到cloze prompt和prefix prompt的区别,在实际应用过程中选择哪一种主要取决于任务的形式和模型的类别。cloze prompts和Masked Language Model的训练方式非常类似,因此对于使用MLM的任务来说cloze prompts更加合适;对于生成任务来说,或者使用自回归LM解决的任务,prefix prompts就会更加合适;Full text reconstruction models较为通用,因此两种prompt均适用。另外,对于文本对的分类,prompt模板通常要给输入预留两个空,[X1]和[X2]。
手工设计模版
代价太大
自动学习模版
分为离散(Discrete Prompts)和连续(Continuous Prompts)两大类。离散的主要包括 Prompt Mining, Prompt Paraphrasing, Gradient-based Search, Prompt Generation 和 Prompt Scoring;连续的则主要包括Prefix Tuning, Tuning Initialized with Discrete Prompts 和 Hard-Soft Prompt Hybrid Tuning。
离散Prompts
自动生成离散Prompts指的是自动生成由自然语言的词组成的Prompt,因此其搜索空间是离散的。目前大致可以分成下面几个方法:
- Prompt Mining. 该方法需要一个大的文本库支持,例如Wikipedia。给定输入x和输出y,要找到x和y之间的中间词或者依赖路径,然后选取出现频繁的中间词或依赖路径作为模板,即“[X] middle words [Z]”。
- Prompt Paraphrasing. Paraphrasing-based方法是基于释义的,主要采用现有的种子prompts(例如手动构造),并将其转述成一组其他候选prompts,然后选择一个在目标任务上达到最好效果的。一般的做法有:将提示符翻译成另一种语言,然后再翻译回来;使用同义或近义短语来替换等。
- Gradient-based Search. 梯度下降搜索的方法是在单词候选集里选择词并组合成prompt,利用梯度下降的方式不断尝试组合,从而达到让PLM生成需要的词的目的。
- Prompt Generation. 既然Prompt也是一段文本,那是否可以用文本生成的方式来生成Prompt呢?该类方法就是将标准的自然语言生成的模型用于生成prompts了。例如,Gao等人将T5引入了模板搜索的过程,让T5生成模板词;Ben-David 等人提出了一种域自适应算法,训练T5为每个输入生成一种唯一的域相关特征,然后把输入和特征连接起来组成模板再用到下游任务中。
- Prompt Scoring. Davison等人在研究知识图谱补全任务的时候为三元组输入(头实体,关系,尾实体)设计了一种模板。首先人工制造一组模板候选,然后把相应的[X]和[Z]都填上成为prompts,并使用一个双向LM给这些prompts打分,最后选取其中的高分prompt。
连续Prompts: P-tuning
直接作用到模型的embedding空间。连续型prompts去掉了两个约束条件:
- 模板中词语的embedding可以是整个自然语言的embedding,不再只是有限的一些embedding。
- 模板的参数不再直接取PLM的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整。
方法:
- Prefix Tuning
- Tuing Initialized with Discrete Prompts
- Hard-Soft Prompt Hybrid Tuning 有关P-tuning的方法
参考
P-tuning 自动构建模版《GPT understands, too》 https://kexue.fm/archives/8295
THUDM P-tuning https://github.com/THUDM/P-tuning
C^3KG: A Chinese Commonsense Conversation Knowledge Graph
构建的中文常识对话知识图谱
4个新的对话流关系:事件流、概念流、情感-原因流、情感-意图流

参考 https://zhuanlan.zhihu.com/p/501111403
BART
生成式预训练模型
与GPT、BERT区别

- GPT是一种Auto-Regressive(自回归)的语言模型。它也可以看作是Transformer model的Decoder部分,它的优化目标就是标准的语言模型目标:序列中所有token的联合概率。GPT采用的是自然序列中的从左到右(或者从右到左)的因式分解。
- BERT是一种Auto-Encoding(自编码)的语言模型。它也可以看作是Transformer model的Encoder部分,在输入端随机使用一种特殊的[MASK]token来替换序列中的token,这也可以看作是一种noise,所以BERT也叫Masked Language Model。
- BART吸收了BERT的bidirectional encoder和GPT的left-to-right decoder各自的特点,建立在标准的seq2seq Transformer model的基础之上,这使得它比BERT更适合文本生成的场景;相比GPT,也多了双向上下文语境信息。在生成任务上获得进步的同时,它也可以在一些文本理解类任务上取得SOTA。
- 训练阶段,Encoder 端使用双向模型编码被破坏的文本,然后 Decoder 采用自回归的方式计算出原始输入;测试阶段或者是微调阶段,Encoder 和 Decoder 的输入都是未被破坏的文本
模型细节
Loss Function: Reconstruction loss 即decoder的输出和原文ground truth之间的cross entropy
BART的结构在上图中已经很明确了:就是一个BERT+GPT的结构,但是有点不同之处在于(也是作者通篇在强调的),相对于BERT中单一的noise类型(只有简单地用[MASK] token进行替换这一种noise),BART在encoder端尝试了多种noise。原因是:
- BERT的这种简单替换导致的是encoder端的输入携带了有关序列结构的一些信息(比如序列的长度等信息),而这些信息在文本生成任务中一般是不会提供给模型的。
- BART采用更加多样的noise(更多无监督预训练任务),意图是破坏掉这些有关序列结构的信息,防止模型去“依赖”这样的信息。

下游任务
得益于auto-regressive的decoder,BART在生成式任务上效果显著。
参考
https://zhuanlan.zhihu.com/p/173858031
https://wmathor.com/index.php/archives/1505/
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
2019 综述文章 Google提出,探索了多种不同的预训练方式,提出了新的数据集和预训练模型T5(Text-to-Text Transfer Transformer)。
“text-to-text” format
一个统一框架,将所有 NLP 任务都转化成 Text-to-Text (文本到文本)任务。
甚至图片中判断语义相似度的任务也是靠输出浮点数来完成的。
通过这样的方式就能将 NLP 任务都转换成 Text-to-Text 形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
无监督任务比较

- Prefix LM: 前半部分用于encoder输入,后半部分用于decoder预测
- MLM
- Deshuffling: 目标是还原整句话

发现还是BERT-Style比较好,随后考虑了BERT-Style的变种
- MASS-Style: 15%的mask全部替换为[mask]
- Replace spans: 替换为mask的范围序列用一个[span-mask]来代替,baseline方法中使用
- Drop tokens: 直接随机删除一些词,然后让模型预测删除的词?
表现都差不多,Replace corrupted spans略好,不需要预测完整序列的方法更好,因为让target更短了。
Corruption rate对比:还是15%最好
 Corruption span长度对比:区别有限,但更高的span长度会加速训练,因为预测target数量更少了。(这里的 [i.i.d.] 是BERT预训练任务中的mask token方法)。在处理非翻译任务上使用 span=3 比 i.i.d. 好一丢丢。
Corruption span长度对比:区别有限,但更高的span长度会加速训练,因为预测target数量更少了。(这里的 [i.i.d.] 是BERT预训练任务中的mask token方法)。在处理非翻译任务上使用 span=3 比 i.i.d. 好一丢丢。
T5预训练模型
- Transformer encoder-decoder模型,用于text-to-text
- Mask方法
- Replace corrupted spans目标
- 15%破坏
- span=3
预训练数据集
C4
训练方法
微调模型所有的参数会导致非最优的结果,这里尝试两种方法,只更新模型的一小部分参数。
adapter layers
在之前 Transformer 的基础上,在每个 block 的每个 feed-forward 层之后加上全新的 dense-ReLU-dense 层。我们只需微调这个层和 layer norm。第二个 dense 层维度被设置为匹配后面的输入,第一个 dense 层的维度考虑赋为不同的值以观察效果。
Adapter layers are additional dense-ReLU-dense blocks that are added after each of the preexisting feed-forward networks in each block of the Transformer.
只要将维度适当地缩放到任务大小,adapter layers 可能是一种在较少参数量上有前途的微调方案。
gradual freezing
随着时间的流逝,从最后一层到所有的层,越来越多的模型参数会进行微调。在 encoder-decoder 模型中,从尾到头并行的解冻 encoder 和 decoder 中的层。而输出分类矩阵和输入嵌入矩阵共享,所以整个过程它们都参与微调
at the start of fine-tuning only the parameters of the final layer are updated, then after training for a certain number of updates the parameters of the second-to-last layer are also included, and so on until the entire network’s parameters are being fine-tuned.
gradually unfreeze layers in the encoder and decoder in parallel, starting from the top in both cases.
效果一般
Multi-task Learning
在预训练阶段对于该模型同时训练多个任务,也即该模型参数在这些任务间共享。但这里只是简单的混合所有预训练数据集
- Example-proportional mixing 人为限制不同任务数据集的最大数量 probability of sampling an example from the mth task during training to $r_m = min(e_m, K)/ \sum min(e_n, K)$ where $K$ is the artificial data set size limit.
- Temperature-sclaed mixing 对每个 $r_m$ 都执行 $1/T$ 次幂,再把它们重新归一化为和为 1 的采样概率。
- Equal mixing 每个数据集采样概率相等
multi-task learning 不如 预训练-微调 的方式
Multi-task Learning与微调结合
Multi-task pretraining + fine-tuning 效果与 Unsupervised pre-training + fine-tuning 相当!
Scaling
如果拥有了 4 倍的计算量,应该如何去使用它?
T5 (Text-to-Text Transfer Transformer)
- Objective 使用平均 span 长度为 3 ,掩码率为 15% 的 span corruption 目标。
- Longer training 使用 C4 数据集预训练 1 million 步, batch size,句子长度为 512,总共大约 1 trillion tokens。
- Model size
| $d_{model}$ | $d_{ff}$ | $d_{kv}$ | head | layer | params | |
|---|---|---|---|---|---|---|
| Small | 512 | 2048 | 64 | 8 | 6 | 60 million |
| Base | 768 | 3072 | 64 | 12 | 12 | 220 million |
| Large | 1024 | 4096 | 64 | 16 | 12 | 770 million |
| 3B | 1024 | 16384 | 128 | 32 | 24 | 2.8 billion |
| 11B | 1024 | 65536 | 128 | 128 | 24 | 11 billion |
- Multi-task pre-training 对每个大小的模型使用不同大小的数据集,再使用 example-proportional mixing 得到多任务的数据集,并对于翻译任务的数据集大小做了适当限制。
- Fine-tuning on individual GLUE and SuperGLUE tasks 对 benchmark 的各个任务单独 fine-tune 可以小幅提升模型性能。为了不在某些 low-resource 任务上过拟合,在 fine-tuning 阶段选择更小的 batch size 为 8,每 1000 步做一次验证。也执行了统一的一次性微调。最终对于每个人物选择统一微调和单独微调中验证效果最好的结果。
- Beam search 对于长输出的句子,使用 beam search 可以提升效果。
- Test set 使用标准的 test set 报道结果(除 SQuAD 之外)
参考:
https://suixinblog.cn/2020/04/t5.html#fn_2
https://zhuanlan.zhihu.com/p/88438851