一些NLP基础知识,方便随时查看
补充知识
混淆矩阵
| TP 真阳性 | FP 假阳性 |
|---|---|
| FN 假阴性 | TN 真阴性 |
表示预测值和真实值之间的差距的矩阵
准确率:$\dfrac{TP+TN}{TP+TN+FP+FN}$,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占90%,负样本占10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到90%的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
Precision精确率:$\dfrac{TP}{TP+FP}$,查准率,它是针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率,意思就是在预测为正样本的结果中,我们有多少把握可以预测正确。
Recall召回率:$\dfrac{TP}{TP+FN}$,查全率,它是针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率。更关心负例的情况下,召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
F1分数=**2*查准率*查全率 / (查准率 + 查全率)**,Precision和Recall二者的平衡
reference: https://www.zhihu.com/question/30643044
N-gram
将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
Subword
传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题:
- 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成;
- 词表中的低频词/稀疏词在模型训练过程中无法得到充分训练
- 一个单词因为不同的形态会产生不同的词,具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。
三种主流的Subword算法:
- Byte Pair Encoding (BPE)
- WordPiece
- Unigram Language Model
BPE
GPT-2和RoBERTa使用的Subword算法都是BPE
步骤:
- 准备足够大的训练语料,并确定期望的Subword词表大小;
- 将单词拆分为成最小单元。比如英文中26个字母加上各种符号,这些作为初始词表;
- 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
- 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1。
举例:
- 语料集:
1 | { |
- 拆分为最小单元,并统计相邻单元频数,最高频数的合并后添加回去
1 | {'l', 'o', 'w', 'e', 'r', 'n', 'w', 's', 't', 'i', 'd', '/w'} |
- 继续上述迭代直到达到预设的Subword词表大小或下一个最高频的字节对出现频率为1
WordPiece
Bert模型在分词时使用WordPiece算法。与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
步骤:
- 假设句子$S=(t_1, t_2, …, t_n)$ 由 $n$ 个子词组成,$t_i$ 表示子词,独立,则句子 $S$ 的语言模型似然值等价于所有子词概率的乘积 $\mathrm{log}P(S)=\sum^n_{i=1}\mathrm{log}P(t_i)$
- 假设把相邻位置的x和y两个子词合并,合并后的子词记为z,此时句子 $S$ 的似然值变化表示为:$\mathrm{log}P(t_z)-(\mathrm{log}P(t_x)+\mathrm{log}P(t_y))=\mathrm{log}(\frac{P(t_z)}{P(t_x)P(t_y)})$
WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
ULM
先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
模型
预训练
一个任务A,一个任务B,二者相似,任务A已经训练出一个模型A,使用模型A的浅层参数去训练任务B,得到模型B。
- fine-tuning 微调:浅层参数跟着任务B训练变化
- 冻结:浅层参数不变
任务 A 对应的模型 A 的参数不再是随机初始化的,而是通过任务 B 进行预先训练得到模型 B,然后利用模型 B 的参数对模型 A 进行初始化,再通过任务 A 的数据对模型 A 进行训练。注:模型 B 的参数是随机初始化的。
统计语言模型
条件概率
神经网络语言模型
one-hot 编码
词向量(神经网络语言模型的副产品) Q矩阵
任何一个词,独特编码w1,w1 * Q = c1 得到词向量word embedding值,可获得词之间的相关性
Word2Vec
重点是得到一个Q矩阵
CBOW
给出一句话上下文,预测这个词(有点像BERT-MLM)
Skip-gram
给出一个词,得到这个词的上下文
缺点
Q矩阵的设计不能多意apple->苹果/iPhone,静态embedding
ELMo(专门做词向量,通过预训练)
解决多义词问题,根据当前上下文对 Word Embedding 动态调整的思路
不只是训练一个Q矩阵,同时把这个词的上下文信息融入到Q矩阵中。ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的LSTM网络结构。

把三层的信息叠加
Attention注意力
Q、K、V,计算 Query 和 Values 中每个信息的相关程度。

将 Query(Q) 和 key-value pairs(把 Values 拆分成了键值对的形式) 映射到输出上,其中 query、每个 key、每个 value 都是向量,输出是 V 中所有 values 的加权,其中权重是由 Query 和每个 key 计算出来的,计算方法分为三步:
- 计算比较 Q 和 K 的相似度,用 f 来表示:$f(Q, K_i), i=1,2…m$,一般第一步计算方法包括四种
- 点乘(Transformer使用):$f(Q,K_i)=Q^TK_i$
- 权重:$f(Q,K_i) = Q^TWK_i$
- 拼接权重:$f(Q,K_i)=W[Q^T:K_i]$
- 感知机:$f(Q,K_i)=V^T\mathrm{tanh}(WQ+UK_i)$
- 将得到的相似度进行 softmax 操作,进行归一化$\alpha_i=\mathrm{softmax}(\frac{f(Q,K_i)}{\sqrt{d_K}})$
- 针对计算出来的权重$\alpha_i$,对 V 中的所有 values 进行加权求和计算,得到 Attention 向量:$\mathrm{Attention}=\sum^m_{i=1}\alpha_iV_i$
Self-Attention 自注意力
Q/K/V同源,同一个X的三个线性变换

$Z_i$是$X_i$的新的词向量表达
Masked Self-Attention 掩码自注意力
生成模型的改进,一个一个单词生成
Multi-head Self-Attention 多头自注意力
一般$h=8$,对于X,不是直接得到Z,而是分成8块,得到$Z_0-Z_7$,然后把$Z_0-Z_7$拼接起来,再做一次线性变换得到Z。
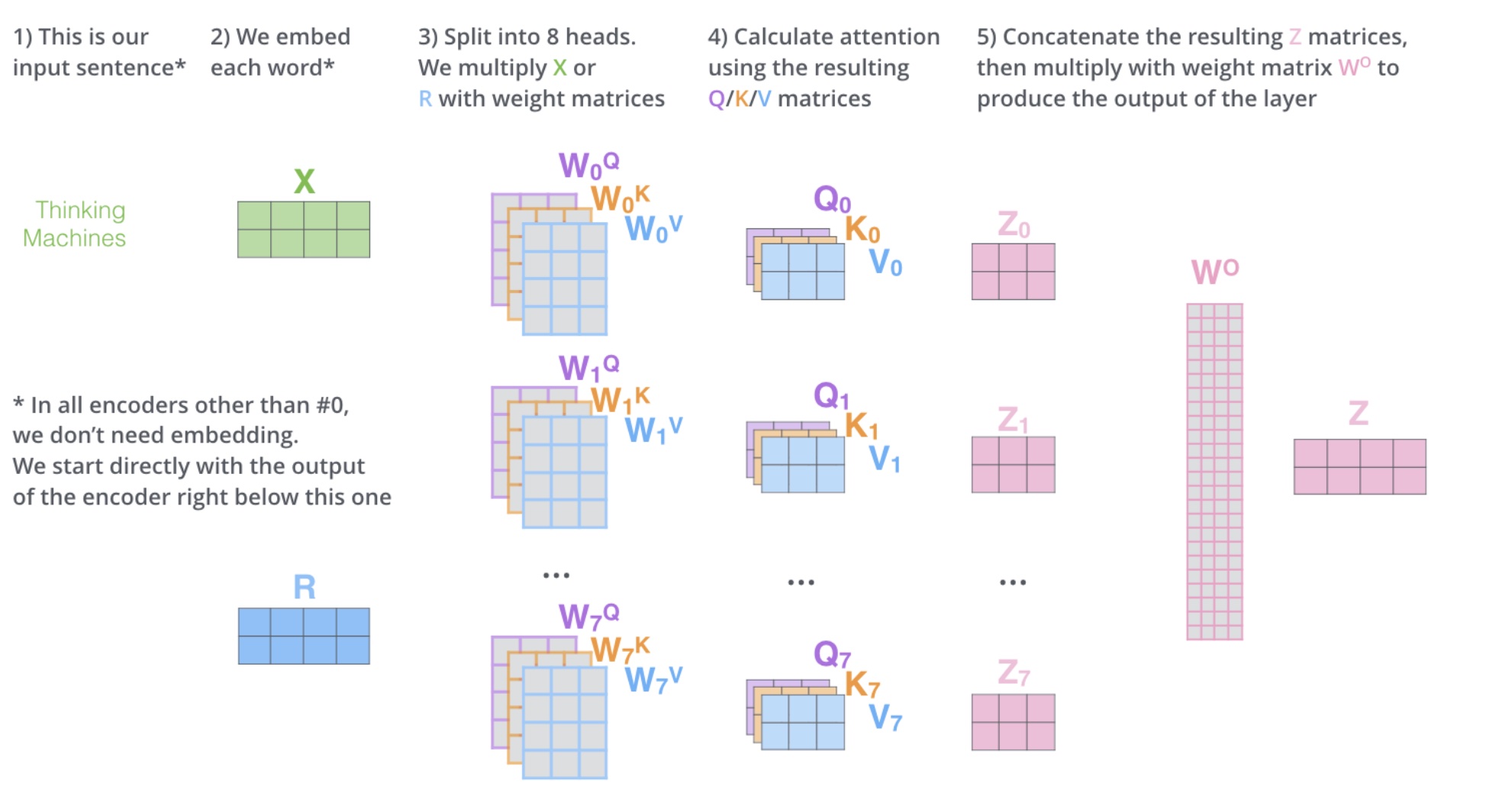
多头相当于把原始信息 Source 放入了多个子空间中,也就是捕捉了多个信息,对于使用 multi-head(多头) attention 的简单回答就是,多头保证了 attention 可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。
Positional Embedding
解决attention中的无位置关系的问题,交换单词位置后 attention map 的对应位置数值也会进行交换,并不会产生数值变化,即没有词序信息。
sin/cos函数隐含位置信息
而且位置信息是与文本无关的,即不管输入什么文本,第i个词的PE都是一样的
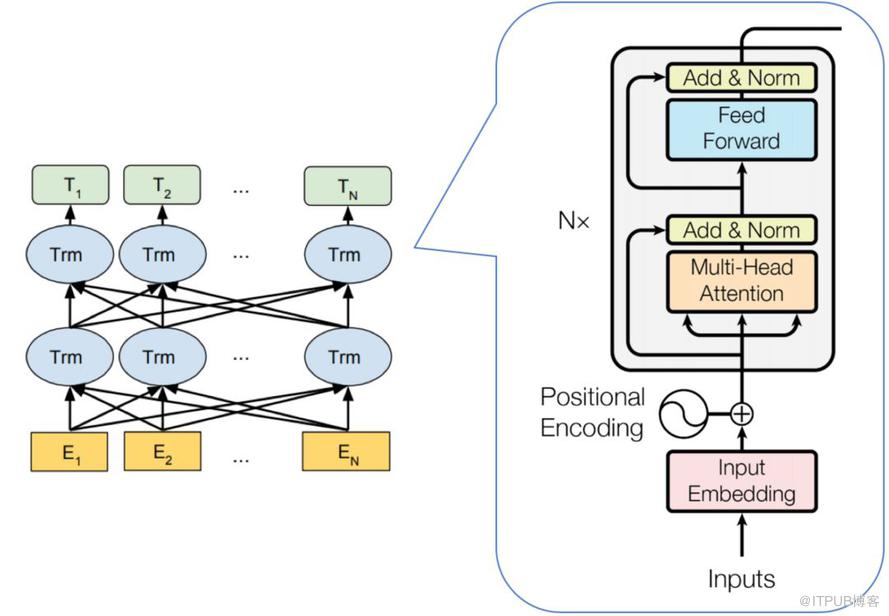
Transformer
seq2seq
Encoder-Decoder模型
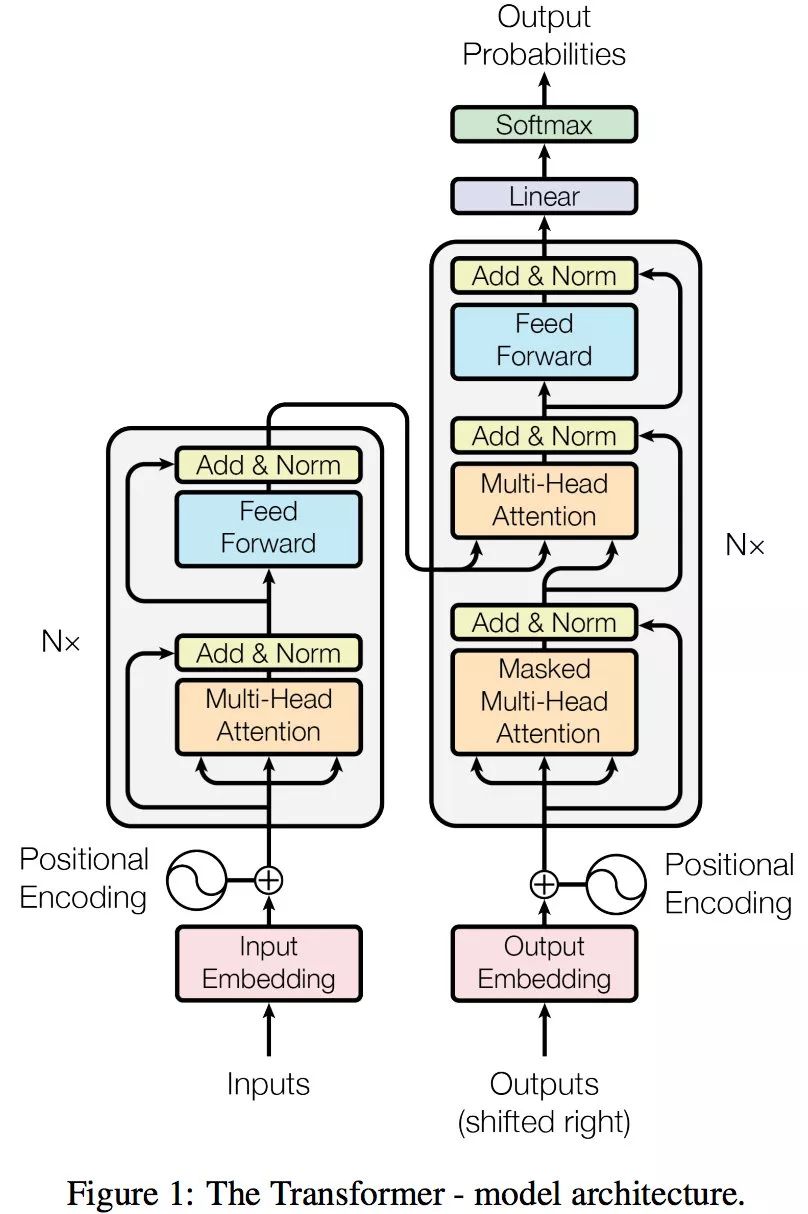
Encoder

- “Thinking”-> 通过one-hot或word2vec等编码得到x1 + 叠加位置编码,输入 Self-Attention 做注意力机制得到 z1。z1 拥有了位置信息、句法特征、语义特征
- x1 作为残差网络(避免梯度消失)的直连向量,直接与 z1 相加,之后进行 LayerNorm(保证数据特征分布的稳定性,并加速模型的收敛)操作,得到 z1
- Feed Forward(非线性潜亏神经网络)中的 ReLU 做非线性变换,加残差网络,得到r1
- r1 会作为”Thinking”的表征输入下一个 Encoder (共6层)
上述的x、z、r 都具有相同的维数,论文中为 512 维。
通过 Encoder 获得了更好的词向量
Decoder
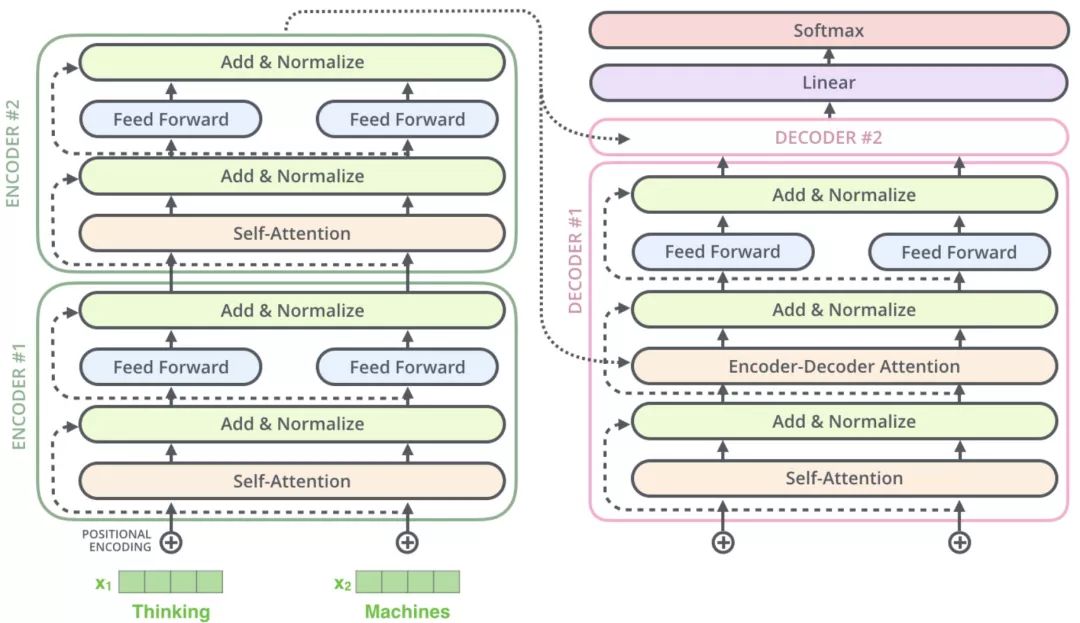
- Masked Self-attention 计算输入的 Self-attention
- Encoder-Decoder Attention 计算,对 Encoder 的输入和 Decoder 的 Masked Self-attention 的输出进行 attention 计算
- 前馈神经网络层,与 Encoder 相同
动态流程
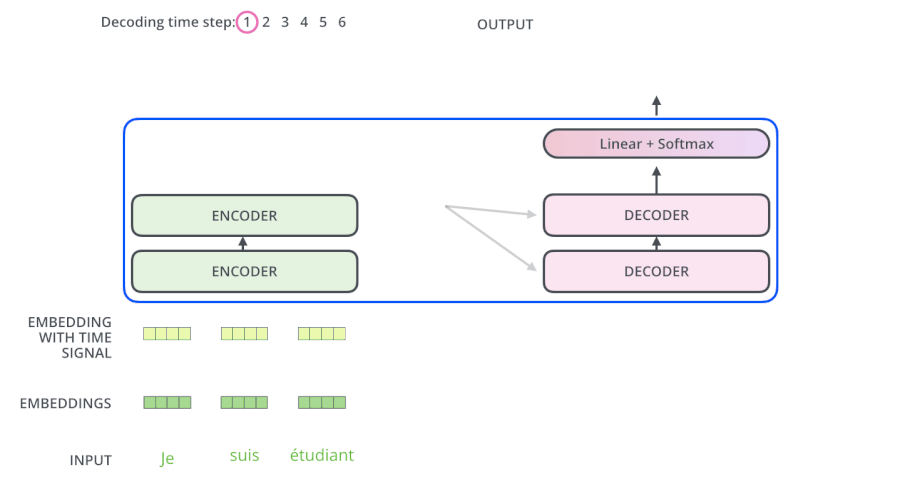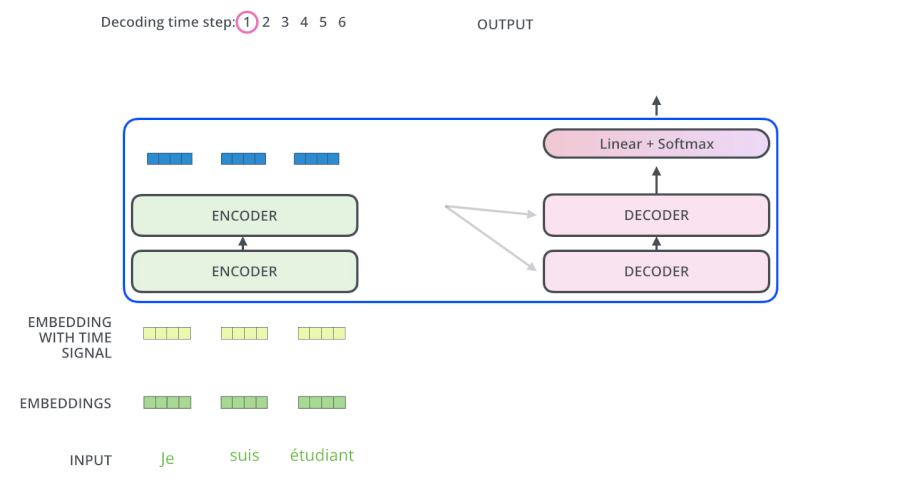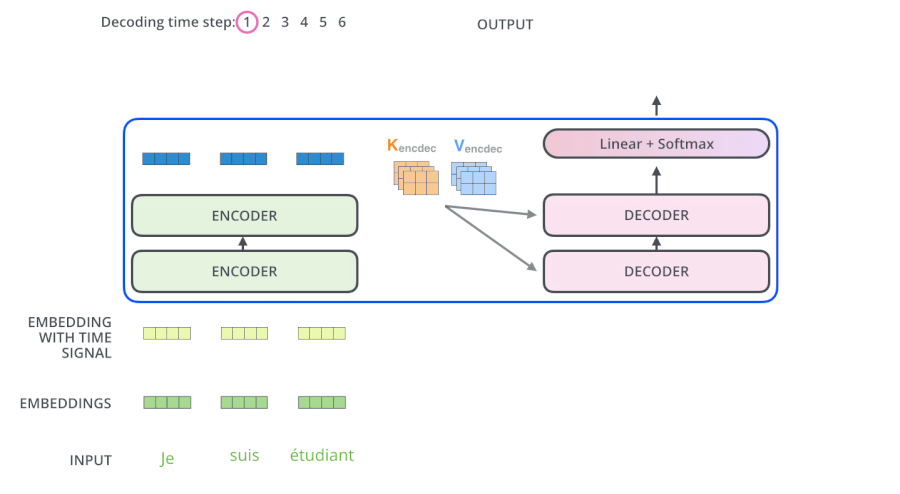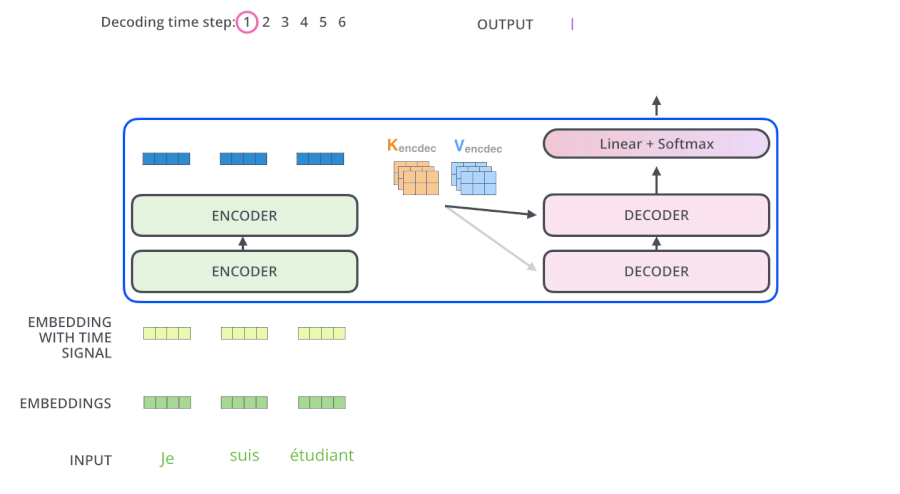
- 输入 “je suis etudiant” 到 Encoders,然后得到一个 $K_e$、$V_e$ 矩阵
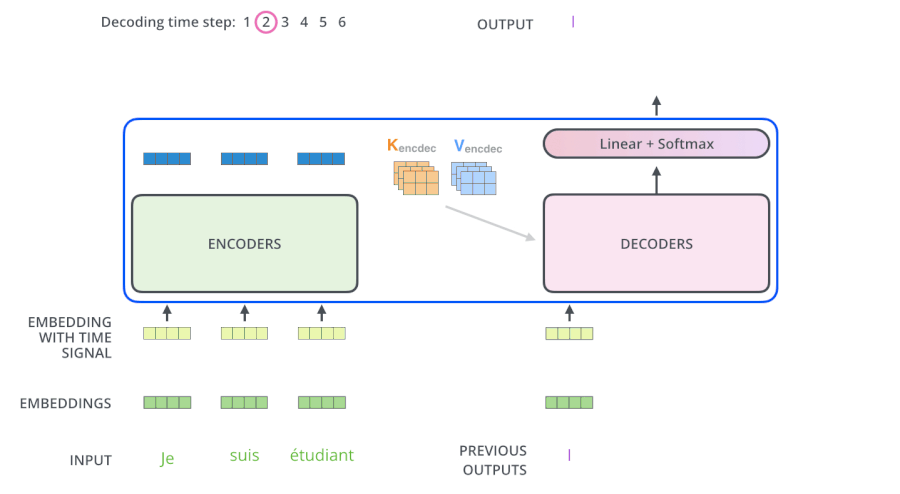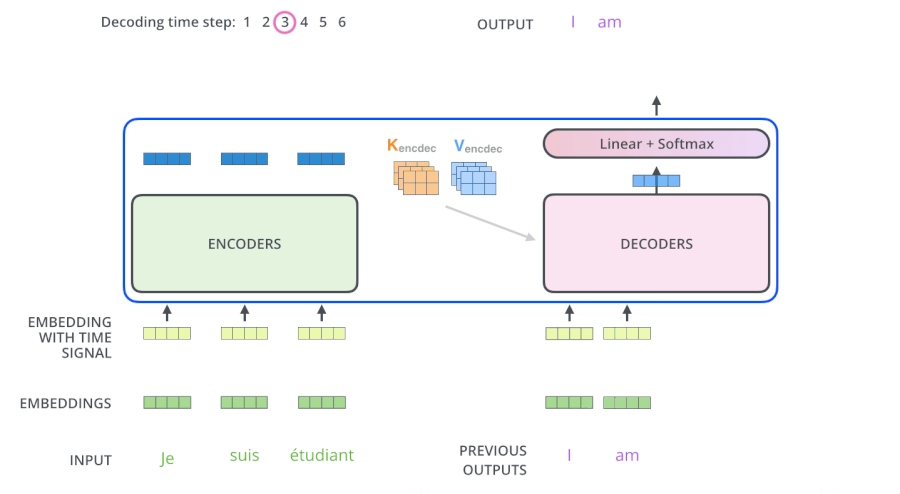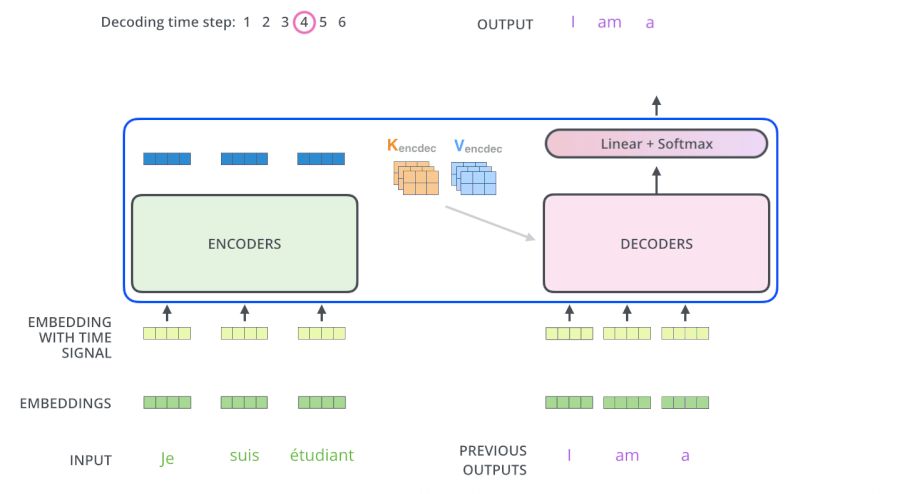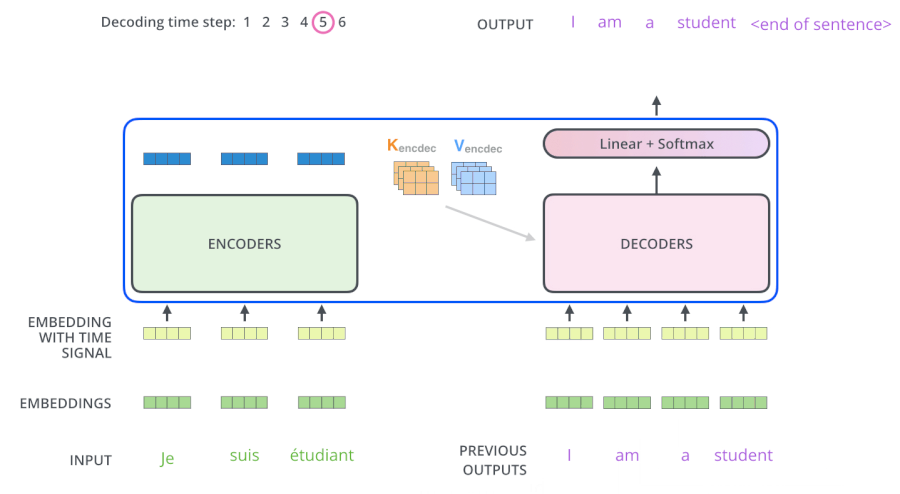
- 输入 “I am a student” 到 Decoders ,首先通过 Masked Multi-head Attention 层得到 “I am a student” 的 attention 值 $Q_d$,然后用 attention 值 $Q_d$ 和 Encoders 的输出 $K_e$、$V_e$ 矩阵进行 attention 计算,得到第 1 个输出 “I”
- 输入 “I am a student” 到 Decoders ,首先通过 Masked Multi-head Attention 层得到 “I am a student” 的 attention 值 $Q_d$,然后用 attention 值 $Q_d$ 和 Encoders 的输出 $K_e$、$V_e$ 矩阵进行 attention 计算,得到第 2 个输出 “am”
Masked Self-Attention 作用:掩蔽decoder的输入
Q 来源于解码器,K=V 来源于编码器,Q是查询变量、已生成的词(或开始符),K=V 是源语句
LayerNorm
Dropout
1 | def dropout(x, level): |
GPT 生成式的预训练
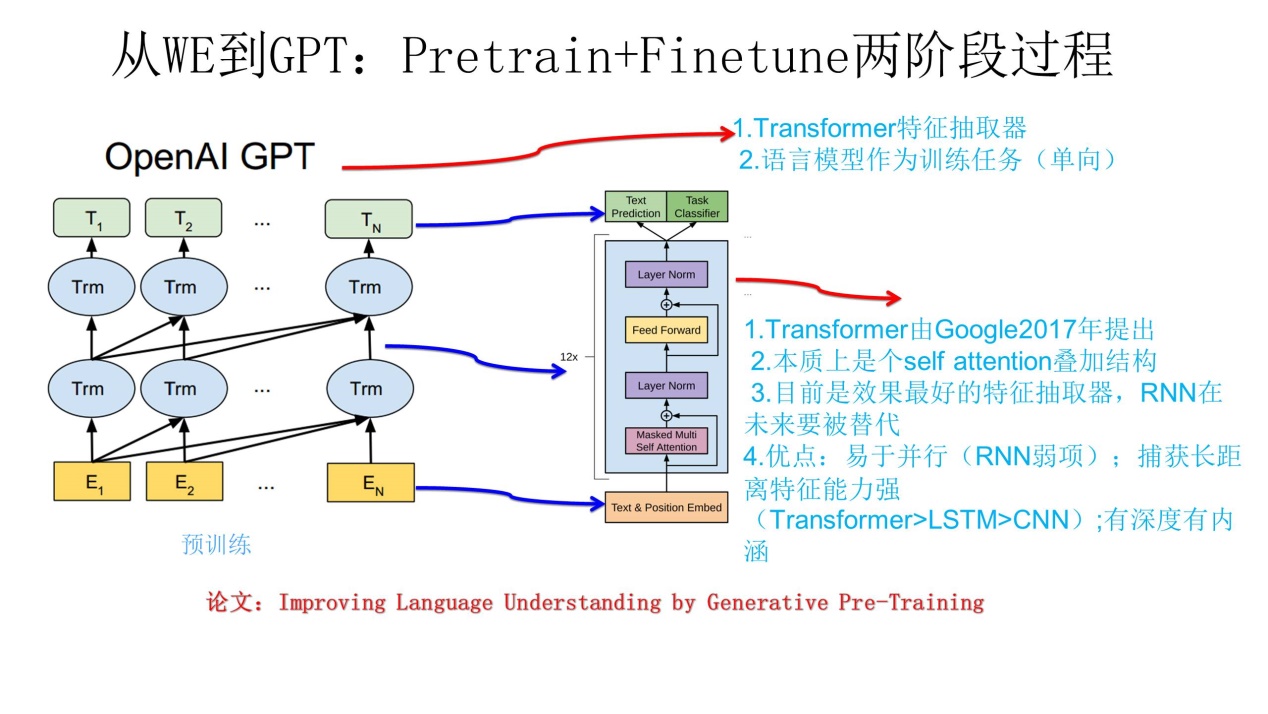
利用语言模型进行预训练,通过fine-tuning解决下游任务。
特征抽取使用 transformer 的 decoder,仅使用单词之前的“上文”来训练(ELMo和BERT使用上下文)

BERT
从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
参考了 ELMO 模型的双向编码思想、借鉴了 GPT 用 Transformer 作为特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法
使用了 Transformer Encoder 作为特征提取器,并使用了与其配套的掩码训练方法。虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强。
BERT 代码参考:https://zhuanlan.zhihu.com/p/360988428