KEPLER 论文笔记
写在前面:因为hexo和typora的垃圾配合,以后的图片都上传到github图床,每篇文章单独写笔记。
KEPLER
A Unified Model for Knowledge Embedding and Pre-trained Language Representation
Abstract
预训练语言模型并不能很好的从文本中提取知识信息。而knowledge embedding方法可以有效的通过信息实体嵌入对知识图谱中的关系信息进行表示,但对大量的语言信息应用有限。本文提出一种 unified model for knowledge embedding and pre-train language representation (KEPLER),不仅可以将知识信息整合到预训练模型中,同时利用PLM生成文本增强的知识表征。
KE(knowledge embedding) methods can provide factual knowledge for PLMs, while the informative text data can also benefit KE.
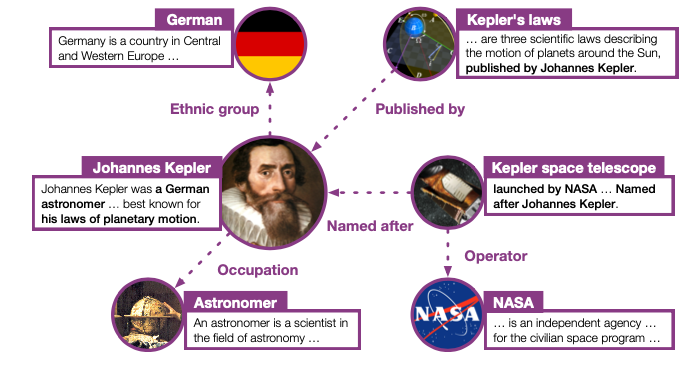
最近的预训练语言模型(PLM)已经在很多NLP任务上取得效果。现有PLMs虽然可以从无标签的文本数据中学习到语意信息,但是通常他们并不能很好的提取world facts,这类信息通常的是稀疏并以复杂的形式在文本中存在。
另一方面,knowledge Graph(KG)包含大量的结构化信息,KE的方法可以有效的将这部分信息放入连续的实体和关系embedding中。这些embedding不仅有助于完善KG同时有利于很多NLP应用。如图一所示,文本实体的描述包含大量的信息。KE可以提供大量的知识信息给PLMs,同时有信息的文本数据有助于KE。
受 Representation Learning 启发,文章用实体描述链接KE和PLM之间的空隙,并将文本语意空间和KG的符号空间对齐(align)。文章提出KEPLER,一种KE和PLM联合模型。方法用同一个PLM作为编码器将文本和实体encode到统一的语意空间中,并同时优化KE和MLM目标函数。
- KE:将实体的描述作为实体的表征并训练
- MLM:沿用现有方法(如:BERT)
优势:
通过对KG有监督地学习,融合知识信息
通过MLM目标继承PLM的强大语言理解能力
KE目标增强了KEPLER从文本中提取知识的能力
enhances the ability of KEPLER to extract knowledge from text since it requires the model to encode the entities from their corresponding descriptions.
可直接适用于很多NLP任务
提出了一个新的数据集 Wikidata5M
模型
Encoder
Transformer 结构
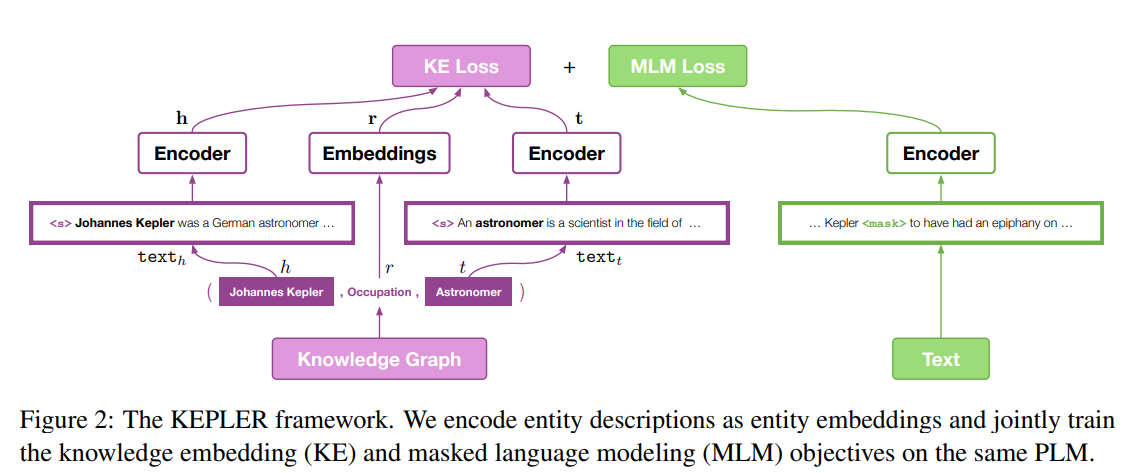
Knowledge Embedding
kg: {(h,r,t)} 三元组集合
传统 KE 模型中:为每一个entity和relation分配一个 d 维向量(embedding),定义一个损失函数来训练这些embedding
KEPLER中,不使用这样的 stored embedding,而是用entity对应的描述来encode
In KEPLER, instead of using stored embeddings, we encode entities into vectors by using their corresponding text.
探索了三种不同的embedding方式:
- 实体描述作为embedding

交叉熵loss function:
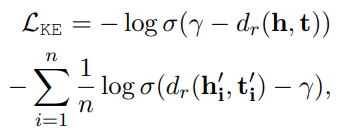
其中 $h’,t’$ 是构造的负类三元组(固定head,随机替换tail或者相反),$d_r(h,t)=||h+r-t||_p$,这里$p=1$,也可以取 2。
- 实体和关系描述作为embedding
上一种方法没有使用关系的描述作为embedding,这里使用,其他与上一种相同。
- 基于关系条件的实体embeding
semantics of an entity may have multiple aspects, and different relations focus on different ones
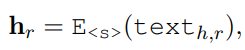
这里 $text_{h,r}$ 是实体 h 和关系 r 的描述的拼接,使用 $h_r$ 代替上面loss function中的 $h$,其他不变
MLM
与 Bert 做法一样
目标
$L=L_{KE}+L_{MLM}$ 两个任务共享一个文本 encoder,但每一个batch的文本数据对 KE 和 MLM 不需要一致。
KEPLER-Wiki
best performance
adopts Wikidata5M as the KG and the entity-description-as-embedding method
Wikidata5M
Transductive/inductive 数据集:验证集/测试集中的entities是否出现在训练集中,trasnductive中的entities是共享的,inductive中的验证/测试集是随机选择的连通子图,entities不相关。
实验
relation classification
数据集:
TACRED 关系抽取数据集
FewRel 小样本关系抽取
介绍:N way K shot设定,即对于N种关系,每种关系的支持集中包含K个样本。
一个3way-2shot的例子

介绍:https://blog.csdn.net/weixin_41803874/article/details/90960811
Entity typing
Entity typing requires to classify given entity mentions into pre-defined types.
数据集:
- OpenEntity
- 6 entity types and 2,000 instances for training, validation and test each.
- 为什么说只有6种关系类型呢?原文中明明上百来种。
GLUE